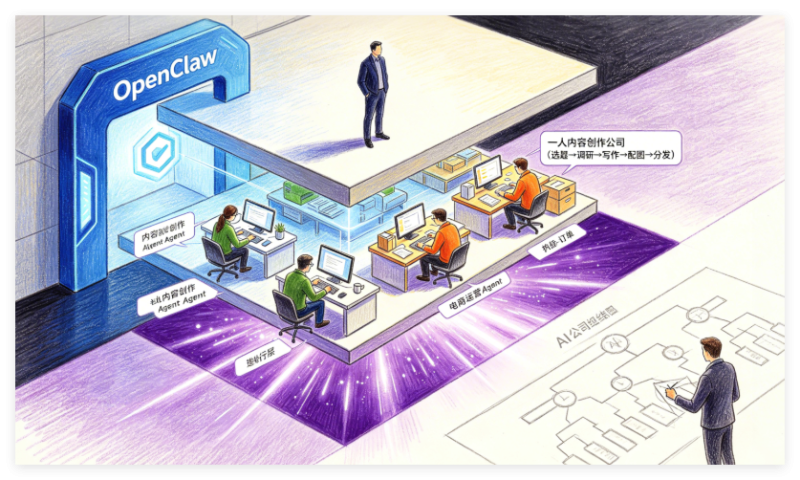









第19章 案例一:一人内容创作公司
本章前置检查:
- □ 理解一人多Agent公司的三层架构(第18章)
- □ 熟悉OpenClaw和Hermes的基础配置(第1-12章)
- □ 了解Skill的开发和安装方法(第4章)
本章预估总时长:4小时
本章难点提示:
- 19.2节的岗位分工表是本章的核心参考,建议先通读再动手配置。
- 19.3节涉及多个Agent的配置文件和渠道绑定,不要一次性全部配置,按“调研→写作→分发”顺序逐个添加并测试。
- 19.4.1节“经验蒸馏”需要Hermes的自动Skill生成能力,确保第10章的内容已掌握。
- 19.5节(量化类比)是为第五篇做铺垫,建议认真阅读并思考如何迁移到量化场景。
🎯 本章教学目标:搭建一个完整的内容创作多Agent系统,涵盖选题、调研、写作、配图、分发全流程,理解Agent间的协作和数据流转,学会将成功经验蒸馏为团队共享Skill,并能够将内容创作模式类比到量化策略研发。
![图片[1]-一人内容创作Agent系统:从热点监测到多平台分发的完全自动化](http://www.ifisme.cn/wp-content/uploads/2026/05/教材1901.png)
19.1 业务流程分析
🎯 本节目标:理清内容创作公司的完整业务链条,识别关键节点和角色。
预计时长:0.5小时
典型内容创作工作流
发现热点 → 选题策划 → 素材收集 → 文章撰写 → 配图制作 → 多渠道分发 → 数据追踪
让我们逐一拆解每个环节的具体任务:
| 环节 | 核心任务 | 涉及的决策点 |
|---|---|---|
| 发现热点 | 监控社交媒体、新闻、论坛,识别潜在爆款话题 | 哪些信号值得关注? |
| 选题策划 | 筛选热点,确定文章角度、目标受众、核心观点 | 写什么?写给谁?什么角度? |
| 素材收集 | 搜集数据、案例、引用、图片素材 | 哪些数据可信?哪些案例典型? |
| 文章撰写 | 根据大纲生成完整文章,多轮润色 | 结构是否合理?语气是否一致? |
| 配图制作 | 生成/搜索/设计配图,优化视觉 | 什么风格?多少张? |
| 多渠道分发 | 发布到微信公众号、知乎、小红书等 | 各平台格式适配、SEO优化 |
| 数据追踪 | 统计阅读量、互动、转化,复盘效果 | 哪些选题受欢迎?哪些渠道高效? |
单人vs多Agent效率对比
| 维度 | 单人完成 | 多Agent协作 |
|---|---|---|
| 日产量 | 1-2篇 | 5-8篇 |
| 平均耗时/篇 | 3-4小时 | 45分钟 |
| 风格一致性 | 依赖个人状态 | Agent记忆保证一致 |
| 热点响应速度 | 人工监测,延迟 | 7×24监控,秒级响应 |
| 知识沉淀 | 靠个人回忆 | 自动Skill固化 |
龙马注:这个差距不是理论值,是我自己跑出来的实测数据。最初我写一篇技术博客要3小时,现在让选题Agent抓热点、调研Agent整理素材、写作Agent生成初稿、我只需修改润色20分钟。配图和分发也自动化了。关键是每个Agent只做自己最擅长的事,互不干扰。
🛠️ 实践任务(本节):列出你日常内容创作中耗时最多的3个环节,思考哪些可以交给Agent。
💭 本节总结(不看书写3行):
📊 用时记录:计划____min → 实际____min → 偏差原因:________
19.2 岗位设置与Agent分工
🎯 本节目标:根据业务流程,拆解出6个核心Agent角色,明确各自的职责、输入输出和协作方式。
预计时长:0.8小时
Agent角色映射表
| Agent名称 | 类型 | 平台 | 职责 | 输入 | 输出 | 所需Skill |
|---|---|---|---|---|---|---|
| 热点监测Agent | 监控 | OpenClaw | 定时抓取RSS/社交媒体/新闻,识别高热度话题 | 关键词列表 | 热点事件列表(含热度评分) | web_search, rss_reader |
| 选题策划Agent | 决策 | Hermes | 分析热点,确定选题方向、目标受众、核心观点 | 热点事件 | 选题卡片(含标题选题、大纲、关键词) | 选题分析Skill |
| 调研Agent | 研究 | Hermes | 搜集数据、案例、引用,整理成结构化素材 | 选题卡片 | 素材包(Markdown格式) | web_search, web_fetch, 素材整理Skill |
| 写作Agent | 创作 | Hermes | 根据大纲和素材生成文章,多轮润色 | 素材包 + 风格偏好 | 文章初稿 | 写作Skill(可自定义风格) |
| 配图Agent | 设计 | OpenClaw | 生成/搜索/优化配图 | 文章关键词、风格 | 图片文件/URL | image_generation, image_search |
| 分发Agent | 发布 | OpenClaw | 适配各平台格式,发布并记录链接 | 文章+配图 | 发布状态+链接 | platform_adapter |
| 数据分析Agent(可选) | 复盘 | Hermes | 收集阅读/互动数据,分析效果,提出改进建议 | 发布链接 | 周报/月报 | data_analysis, web_fetch |
协作流程时序
定时触发 (Cron)
↓
[热点监测Agent] → 热点列表写入共享记忆(L2)
↓
[选题策划Agent] 读取热点 → 选题卡片 → 写入共享记忆
↓
[调研Agent] 读取选题卡片 → 素材包 → 写入共享文件
↓
[写作Agent] 读取素材包 → 文章初稿 → 写入共享文件
↓
[配图Agent] 读取文章关键词 → 图片 → 写入共享文件
↓
[分发Agent] 读取文章+图片 → 发布到多平台 → 记录链接
↓
[数据分析Agent] (每周一次) 读取链接 → 分析报告 → 推送
渠道与权限设计
- 热点监测Agent:只读网络,无文件写权限 → 仅输出到共享队列。
- 选题策划Agent:可读写共享记忆,无工具调用 → 纯LLM决策。
- 调研Agent:可读写文件,有web工具 → 需要网络访问。
- 写作Agent:可读写文件,无网络 → 只访问素材文件。
- 配图Agent:可读写文件,有图像生成工具 → 需要图像API。
- 分发Agent:可读写文件,有渠道API → 需要各平台Token。
- 数据分析Agent:可读写文件,有数据分析工具 → 仅限内部统计。
沈飞注:这个权限设计体现了“最小权限原则”。写作Agent不需要网络,配图Agent不需要访问用户隐私数据,分发Agent只能写到指定目录。即使某个Agent被攻破,损失范围也很小。
🛠️ 实践任务(本节):为你的内容创作Agent团队画出协作流程图(可用Draw.io或手绘),标注每个Agent的输入/输出存储位置。
💭 本节总结(不看书写3行):
📊 用时记录:计划____min → 实际____min → 偏差原因:________
19.3 完整配置与实现步骤
🎯 本节目标:动手搭建内容创作Agent团队,逐个配置Agent、Skill、共享记忆和Cron调度。
预计时长:1.5小时
步骤1:准备共享记忆空间
创建共享目录和记忆库(L2级别):
bash
mkdir -p /mnt/content_agent_shared/{inbox,outbox,memory}
cd /mnt/content_agent_shared
# 初始化记忆JSON文件
echo '{"hot_items": [], "topics": [], "materials": {}, "articles": {}}' > memory/state.json
步骤2:配置热点监测Agent(OpenClaw Cron)
在OpenClaw中创建一个Cron任务,每小时抓取热点:
bash
openclaw cron add \ --name "hotspot_monitor" \ --cron "0 * * * *" \ --tz Asia/Shanghai \ --message "抓取微博热搜、知乎热榜、Hacker News,提取前10条热点,计算热度分数(0-100),输出JSON格式,写入 /mnt/content_agent_shared/inbox/hotspots.json"
验证:等待第一个整点,检查/mnt/content_agent_shared/inbox/hotspots.json是否有内容。
步骤3:配置选题策划Agent(Hermes Skill + Cron)
创建一个Hermes Skill:topic_planner。
SKILL.md(部分):
markdown
--- name: topic_planner description: 根据热点事件生成选题卡片 --- ## 执行步骤 1. 读取 /mnt/content_agent_shared/inbox/hotspots.json 2. 选择热度>70的事件 3. 为每个事件生成选题卡片: - 选题标题 - 目标受众 - 核心观点 (3个) - 建议大纲 (1-2级标题) - 关键词 (3-5个) 4. 写入 /mnt/content_agent_shared/outgoing/topics.json
创建Cron任务,每小时触发一次(在热点更新后):
bash
hermes cron add "5 * * * *" "运行topic_planner技能生成选题" --tz Asia/Shanghai
步骤4:配置调研Agent(Hermes)
bash
hermes skill create researcher --from-template research # 编辑 ~/.hermes/skills/researcher/SKILL.md,定义读取选题、搜索网页、整理素材的流程
步骤5:配置写作Agent(Hermes)
写作Agent需要加载用户风格偏好(从共享记忆USER.md读取)。在~/.hermes/memories/USER.md中添加:
markdown
## 写作风格 - 语言: 中文,简洁有力 - 段落: 每段不超过5行 - 风格: 技术博客,带代码示例 - 禁用词: "非常""极其""特别"
写作Skill示例如下(SKILL.md片段):
markdown
## 工作流
1. 读取 /mnt/content_agent_shared/outgoing/materials/{topic_id}.md
2. 加载用户风格偏好(从USER.md)
3. 按以下结构生成文章:
- 标题 (H1)
- 引言 (2-3句吸引注意)
- 正文 (按大纲展开,每部分配一个小标题)
- 结论 (总结+行动号召)
4. 写入 /mnt/content_agent_shared/outgoing/articles/{topic_id}.md
步骤6:配置配图Agent与分发Agent(OpenClaw Skill)
配图Skill可调用外部图像生成API,分发Skill需为每个平台编写适配器。由于篇幅,完整代码见附录P示例。
步骤7:配置数据分析Agent(周复盘)
bash
hermes cron add "0 9 * * 1" "分析上周发布文章的阅读、点赞、评论数据,生成效果报告并推送飞书" --tz Asia/Shanghai
步骤8:整合调度(可选:使用低代码编排)
在n8n或Dify中,将上述各Cron任务串联成一个工作流,并加入人工审核节点(如果你希望在发布前审阅文章)。详细配置见附录P。
龙马注:不要一次性把所有步骤配置完再测试。我的顺序是:先配热点监控→手动运行一次确认有数据→配选题策划→手动测试→配调研→手动测试…每加一个Agent,就验证上一步的输出能被下一步正确读取。这样调试效率最高。
🛠️ 实践任务(本节):按照上述步骤,至少完成热点监测、选题策划和调研三个Agent的配置,并手动触发一次完整流程。
💭 本节总结(不看书写3行):
📊 用时记录:计划____min → 实际____min → 偏差原因:________
19.4 效果评估与迭代优化
🎯 本节目标:建立内容创作质量评估体系,持续优化Agent协作效果。
预计时长:0.5小时
质量评估指标
| 指标 | 目标值 | 测量方法 |
|---|---|---|
| 选题采纳率 | >60% | 团队(你)从选题列表中采纳的比例 |
| 素材完整度 | >90% | 调研产出的大纲是否覆盖所有要点 |
| 初稿修改次数 | <3次 | 文章从生成到发布需修改的轮数 |
| 风格一致性 | 用户评价 | 与历史文章对比,语气、格式是否一致 |
| 端到端耗时 | <45分钟 | 从热点触发到文章发布 |
迭代优化流程
Step 1:收集反馈
- 数据分析Agent每周自动生成报告,标注低阅读量文章所属的选题、写作Agent、配图风格。
- 人工标记“优秀文章”和“失败文章”。
Step 2:更新Skill
- 对优秀文章,让Hermes执行
skill_manage(action='patch', skill='writer'),将成功的写作模式注入Skill。 - 对失败文章,分析原因:如果是调研不充分,改进调研Skill;如果是选题差,调整选题策路。
Step 3:A/B测试
- 同时运行两套写作Agent(不同参数或模型),对比产出质量,保留胜者。
19.4.1 经验蒸馏:让调研Agent的选题技巧自动沉淀为写作Agent的灵感库
本节演示如何通过共享记忆实现Agent间经验复用。
场景:调研Agent在搜集素材时,偶然发现一组高质量的数据源或写作角度,希望写作Agent下次能直接使用。
实现:
- 调研Agent在完成任务后,自动调用
memory工具将“有价值的发现”写入共享记忆的L3层(外部提供商或JSON文件)。 - 写作Agent在开始新文章前,先查询共享记忆中的“灵感库”,将相关提示注入系统提示词。
- 每周运行一次
memory_evaporator脚本,分析灵感库中最频繁出现的模式,生成新的写作模板(Skill)。
示例代码(调研Agent的SKILL.md片段):
markdown
## 执行步骤
...
4. 如果发现特别优质的数据来源或写作角度,调用:
memory(action="add", target="user",
content="灵感: 关于XX主题,可以使用YY数据源,发现ZZ趋势。")
效果:写作Agent在后续相关主题写作时,会自动检索到这些灵感并运用。
沈飞注:这个经验蒸馏机制在量化场景中威力巨大——因子挖掘Agent发现的有效因子构建模式,可以自动沉淀到因子库,供策略Agent直接调用。我们稍后在第五篇会详细展开。
🛠️ 实践任务(本节):
- 运行一周的内容创作Agent系统,收集数据,分析瓶颈环节。
- 针对最慢的环节(如调研耗时过长),尝试优化对应Skill或增加并行Agent。
💭 本节总结(不看书写3行):
📊 用时记录:计划____min → 实际____min → 偏差原因:________
19.5 🔗 量化场景类比:内容创作流水线与量化因子挖掘流水线
🎯 本节目标:将内容创作公司的多Agent架构映射到量化策略研发,为第五篇做铺垫。
预计时长:0.3小时
核心映射关系
| 内容创作环节 | 对应量化策略研发环节 |
|---|---|
| 热点监测Agent | 行情数据监控Agent(实时价格、成交量、新闻情绪) |
| 选题策划Agent | 因子挖掘Agent(发现有效预测信号) |
| 调研Agent | 因子回测与验证Agent(历史数据验证) |
| 写作Agent | 策略组合与执行Agent(生成交易信号) |
| 配图Agent | 可视化报告Agent(生成图表、归因分析) |
| 分发Agent | 交易执行Agent(下单到券商) |
| 数据分析Agent | 绩效归因Agent(分析策略盈亏来源) |
协作模式的可复用性
- 流水线串行
内容创作中“热点→选题→素材→写作”的顺序,与量化中“数据→因子→信号→交易”完全对应。你可以重用相同的ACP委托模式。 - 记忆蒸馏
内容创作中的“灵感库”机制,可直接移植为量化中的“因子池”——因子挖掘Agent发现的候选因子,写入共享因子库,策略Agent从中选择使用。 - 质量评估与迭代
内容创作中的“采纳率”“修改次数”指标,对应量化中的“因子IC”“夏普比率”“最大回撤”。低质量的因子自动淘汰,高质量因子固化到Skill。 - 多Agent并行
多个调研Agent可同时工作(并行采集不同信源),类似多个因子回测Agent并行计算不同因子组的绩效。
从本节到第五篇的迁移清单
当你完成内容创作Agent团队后,你已经掌握了:
- 多Agent协作的流水线设计
- 共享记忆的读写和并发控制
- Skill的质量治理与迭代
- 经验蒸馏与知识复用
这些技能在量化系统中几乎原样复用。在第五篇,你只需:
- 替换数据源(新闻→行情数据)
- 替换工具集(web_search→quant_data_api, 写作Skill→回测Skill)
- 调整评估指标(阅读量→夏普比率)
- 强化风控Agent(内容不需要,量化必须)
龙马注:我最初搭建量化Agent系统时,就是直接把内容创作的这套架构拿过来改的。代码结构几乎一样,只是换了工具和Skill。所以不要觉得“金融量化”很遥远,你离它只差一个数据源的转换。
🛠️ 实践任务(本节):思考你所在行业或兴趣领域的业务,能否也用类似的流水线结构拆解?写出3个环节→Agent的映射。
💭 本节总结(不看书写3行):
📊 用时记录:计划____min → 实际____min → 偏差原因:________
19.6 (可选)内容矩阵扩展:增加视频脚本Agent和社交媒体分发Agent
🎯 本节目标:展示如何低成本扩展Agent团队,增加新的内容形式。
预计时长:0.2小时
如果你的业务需要短视频脚本或社交媒体短文案,可以轻松添加两个新Agent:
视频脚本Agent
职责:将已有的文章转化为视频脚本(包含旁白、分镜、字幕提示)。
配置:复制写作Agent的配置,修改SKILL.md:
markdown
## 工作流 1. 读取文章内容 2. 按场景拆解为3-5个分镜 3. 为每个分镜撰写旁白文本(60-100字) 4. 标注视觉建议(如“展示数据图表”) 5. 输出脚本JSON格式
社交媒体分发Agent增强
在原分发Agent基础上,增加对抖音、B站、小红书的适配(API调用),将视频自动上传。
扩展后的团队结构:
文章
↓
┌───┴────┐
↓ ↓
写作Agent 视频脚本Agent
↓ ↓
配图Agent → 分发Agent(新增视频平台)
成本:新增一个Hermes实例(或复用现有),新增一个Skill,修改渠道配置——一天内可完成。
龙马注:这就是一人多Agent公司的魅力。一旦基础流水线搭好,增加新的内容形式就像招聘一个“新员工”,配置好岗位职责(SKILL.md)后即刻上岗,不需要培训、不需要磨合。
🛠️ 实践任务(本节):(可选)如果你有视频内容需求,按上述步骤创建视频脚本Agent并测试。
💭 本节总结(不看书写3行):
📊 用时记录:计划____min → 实际____min → 偏差原因:________
第19章 参考资料与扩展阅读
- 一人公司:内容创作的AI自动化实战(阿里云) https://developer.aliyun.com/article/1730228
- Hermes Memory蒸馏在内容创作中的应用 https://hermes-agent.nousresearch.com/docs/use-cases/content-distillation
- OpenClaw Cron多任务调度最佳实践 https://docs.openclaw.ai/zh-CN/automation/cron
- 从内容创作到量化投资:多Agent流水线复用指南 https://www.volcengine.com/docs/87732/2277063
第四篇综合任务(第19章完成后)
任务:完成以下所有检查项。
- 完成热点监测、选题策划、调研三个核心Agent的配置,并手动触发一次完整流程(生成至少一篇素材)。
- 为写作Agent配置风格偏好,验证输出是否符合预期。
- 设置数据分析Agent周报,运行后查看报告内容。
- 尝试在团队中添加一个新Agent(如视频脚本Agent),并测试。
- 思考内容创作流程与量化因子挖掘流程的映射关系,写下至少3条相似点。
完成后,保存配置文件,命名为chapter19_content_agents_config.zip。
龙马的评审:
“19.3节的分步骤配置非常实用,但我补充一个坑:共享记忆的文件路径必须确保OpenClaw和Hermese都能访问。如果你的OpenClaw跑在Docker里,Hermes跑在宿主机,默认路径不共享。解决方案:映射同一个volume,或者改用Redis/PostgreSQL(L2)。
另外,写作Agent的初稿质量很大程度上取决于调研素材的结构化程度。调研Agent最好输出带标题、要点、引用分段的Markdown,而不是纯文本。我在素材整理Skill里加了“按大纲二级标题组织内容”的规则,写作Agent的输出质量提升非常明显。”
沈飞的评审:
“19.5节的量化类比非常关键。我建议读者在学完本章后,立刻尝试把内容创作Agent的代码框架复制一份,把‘选题’改成‘因子挖掘’、‘写作’改成‘回测’、‘分发’改成‘下单’。你会发现,除了工具调用不同,整个协作模式和记忆蒸馏机制完全复用。这就是我们为什么在第四篇安排三个通用案例——它们是第五篇的脚手架,而不是孤立的例子。
另外,19.4.1节的经验蒸馏机制,在量化中可以用来构建‘因子库Agent’。当因子挖掘Agent发现高IC的因子时,自动调用 memory工具存入库中;策略Agent每次运行前查询因子库,自动选择最优因子组合。这种‘自动化因子迭代’是前沿量化团队的标志性能力。”
下一章预告:第20章 案例二:一人电商运营公司 —— 我们将学习如何用多Agent实现价格监控、竞品分析、自动调价和客服响应,同样会给出与量化风控的类比。













暂无评论内容