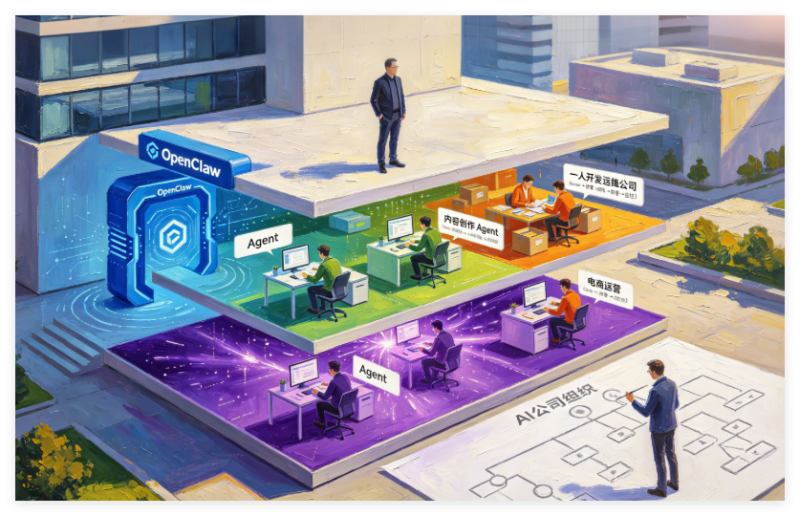









第21章 案例三:一人开发运维公司
本章前置检查:
- □ 理解一人多Agent公司的三层架构(第18章)
- □ 熟悉OpenClaw的Cron定时任务和Heartbeat心跳巡检(第6章)
- □ 熟悉Hermes的子Agent委托机制(第11章)
- □ 了解MCP协议的GitHub集成(第14章)
本章预估总时长:4小时
本章难点提示:
- 21.2节的岗位分工引入了“Supervisor Agent”作为多Agent调度的“大脑”,这是本章的核心模式——一个OpenClaw Agent来协调多个专业运维Agent的分工与协作。
- 21.3节的CI/CD自动化涉及GitHub MCP Server和Docker后端的配置,建议先通读全文再动手,避免因配置顺序错误导致部署失败。
- 21.4节的故障自愈中,“检查点回滚”与“熔断机制”是生产环境的关键保障,务必理解其触发条件和执行权限。
- 21.6节的量化类比是第五篇的重要桥梁,建议认真思考故障自愈与量化风控的相似性。
🎯 本章教学目标:搭建一个完整的一人开发运维多Agent系统,涵盖GitHub PR自动化处理、CI/CD流程、服务器监控、智能故障诊断与自愈,理解Supervisor Agent的层级调度模式,掌握故障自愈与熔断机制的设计,并能够将开发运维模式类比到量化交易中的策略部署与风控。
![图片[1]-一人传媒内容创作公司实战:用OpenClaw+Hermes搭建多Agent内容生产流水线](http://www.ifisme.cn/wp-content/uploads/2026/05/教材2101.png)
21.1 业务流程分析
🎯 本节目标:理清开发运维公司的完整业务链条,识别可自动化的关键节点。
预计时长:0.5小时
典型开发运维工作流
需求接收 → 代码开发 → 测试验证 → 代码审查 → 构建打包 → 部署上线 → 运行监控 → 故障排查 → 文档更新
逐一拆解每个环节的核心任务:
| 环节 | 核心任务 | 可自动化程度 | 建议Agent角色 |
|---|---|---|---|
| 需求接收 | 解析GitHub Issue/PR,理解任务目标 | 高 | 调度Agent(OpenClaw Team Lead) |
| 代码开发 | 生成代码、修复Bug、重构优化 | 高 | 开发Agent(Hermes) |
| 测试验证 | 运行单元测试、集成测试、回归测试 | 高 | 测试Agent(OpenClaw子Agent) |
| 代码审查 | 检查代码风格、潜在Bug、安全性 | 中 | 审查Agent(Hermes) |
| 构建打包 | 编译、打包Docker镜像 | 高 | 构建Agent(OpenClaw) |
| 部署上线 | 推送到测试/生产环境 | 高(需审批) | 部署Agent(OpenClaw) |
| 运行监控 | 健康检查、性能监控、日志收集 | 高 | 监控Agent(OpenClaw) |
| 故障排查 | 定位问题根源、分析日志、给出修复方案 | 中 | 诊断Agent(Hermes) |
| 文档更新 | 更新API文档、操作手册、发布说明 | 高 | 文档Agent(Hermes) |
单人vs多Agent开发运维效率对比
| 维度 | 单人运维 | 多Agent协作 |
|---|---|---|
| 服务发布耗时 | 5-10分钟 | 30秒-2分钟 |
| 故障定位时间 | 15-30分钟 | 30秒-5分钟 |
| 监控覆盖率 | 人工抽查(有限) | 7×24全量覆盖 |
| 文档同步延迟 | 数天至一周 | 自动同步 |
| 并发处理能力 | 1个任务 | 5+任务并行 |
龙马注:这个效率提升不是理论值。我现在每天到公司第一件事就是看“小龙虾”发在群里的早巡检报告:各环境服务状态、磁盘使用率、API延迟,一目了然。以前需要花1小时登录各个服务器查看,现在30秒读完报告。更重要的是,凌晨3点收到服务告警,Agent会自动检查日志、尝试重启,45秒内恢复,我不需要被叫醒。
21.2 岗位设置与Agent分工
🎯 本节目标:根据业务流程拆解开发运维所需的Agent角色,引入Supervisor Agent实现层级调度。
预计时长:0.8小时
Agent角色映射表
| Agent名称 | 类型 | 平台 | 职责 | 输入 | 输出 | 所需Skill/Tool |
|---|---|---|---|---|---|---|
| Supervisor Agent(调度员) | Team Lead | OpenClaw | 解析用户需求,拆分子任务,协调各专业Agent | 自然语言指令 | 任务状态汇总 | delegate_task, 任务拆解Skill |
| GitHub Agent | 交互 | OpenClaw | 监听Issue/PR事件,拉取代码,创建PR | GitHub webhook | PR链接、变更摘要 | github-mcp, git |
| 开发Agent | 执行 | Hermes | 分析代码,修复Bug,编写单元测试 | 代码文件+Issue描述 | 修复后的代码、测试用例 | code_interpreter, file |
| 测试Agent | 验证 | OpenClaw | 运行测试套件,生成覆盖率报告,标记失败 | PR代码 | 测试结果、覆盖率 | terminal, pytest |
| 审查Agent | 分析 | Hermes | 代码风格检查、安全漏洞扫描、复杂度分析 | PR diff | 审查意见(通过/需修改) | code_analysis, security_check |
| 构建Agent | 打包 | OpenClaw | 编译二进制、构建Docker镜像 | 代码+配置 | 镜像tag、构建日志 | docker, terminal |
| 部署Agent | 发布 | OpenClaw | 部署到开发/测试/生产环境(需审批) | 镜像tag、环境 | 部署状态 | kubernetes, ssh |
| 监控Agent | 巡检 | OpenClaw | 健康检查、指标采集、异常告警 | 服务端点 | 健康报告、告警消息 | http, metrics |
| 诊断Agent | 排查 | Hermes | 分析日志、定位根因、建议修复方案 | 错误日志+上下文 | 诊断报告 | web_search, log_analysis |
| 文档Agent | 同步 | Hermes | 根据代码变更更新README、API文档 | commit diff | 文档更新PR | file_write, markdown |
Supervisor Agent:多Agent调度的“大脑”
这是本章的核心模式——你不需要手动触发每个Agent,而是创建一个Supervisor Agent来统筹调度。Supervisor Agent的运行逻辑是:接收自然语言指令 → 解析意图 → 拆分子任务 → 委托给专业Agent → 汇总结果 → 反馈用户。
Supervisor Agent的AGENTS.md示例:
markdown
--- name: DevOps Supervisor role: 开发运维总调度员 type: team_lead --- ## 职责 - 接收用户的所有开发运维需求(自然语言) - 判断任务类型(代码开发/测试/部署/监控/故障排查) - 拆解为子任务,调度对应的专业Agent执行 - 汇总结果,向用户反馈执行状态 ## 任务类型映射 | 用户输入关键词 | 任务类型 | 调度Agent | |--------------|---------|----------| | 修复Bug / 写代码 / 优化 | 代码开发 | 开发Agent | | 跑测试 / 验证 | 测试验证 | 测试Agent | | 部署 / 发布 / 上线 | 部署上线 | 部署Agent | | 检查 / 监控 / 健康 | 运行监控 | 监控Agent | | 出问题了 / 报错 / 排查 | 故障排查 | 诊断Agent | ## 工作流(以部署任务为例) 1. 解析用户需求:识别目标环境(dev/test/prod)和版本 2. 调用测试Agent:确保测试通过,否则中止并反馈 3. 调用构建Agent:生成镜像,记录tag 4. 如需人工审批:发送审批请求到飞书,等待批准 5. 调用部署Agent:执行部署,等待健康检查 6. 汇总结果,生成部署报告推送给用户 ## 约束 - 生产环境部署必须经过人工审批 - 禁止在未运行测试的情况下直接部署 - 所有操作必须有审计日志
Supervisor Agent的调用示例
在OpenClaw中创建Supervisor Agent后,用户只需要在飞书中说一句话:
“@DevOps Supervisor 帮我修复用户反馈的登录超时Bug,测试通过后部署到staging环境”
Supervisor Agent会自动:调用GitHub Agent获取Issue详情 → 调用开发Agent定位分析 → 调用测试Agent验证修复 → 调用部署Agent推送staging。
龙马注:Supervisor Agent是目前我搭建多Agent系统中最常用、也最实用的一种模式。它让你不需要记住“应该找哪个Agent做什么事”,只需要告诉“总管Agent”你想干什么。日常运维中80%的指令都会被自动路由。
🛠️ 实践任务(本节):
- 根据你的项目结构,列出至少5个可以Agent化的运维场景
- 为Supervisor Agent编写任务类型映射表(至少包含4种任务类型)
💭 本节总结(不看书写3行):
📊 用时记录:计划____min → 实际____min → 偏差原因:________
21.3 开发流程自动化:从Issue到PR的全自动流程
🎯 本节目标:配置GitHub MCP Server,实现从Issue创建到PR提交的全自动开发流程。
预计时长:1.2小时
21.3.1 配置GitHub MCP Server(OpenClaw侧)
🔗 量化类比:这段配置完全复用于第五篇的“策略自动上线”场景——把“PR”换成“策略代码”,“GitHub”换成“因子仓库”,流程完全一样。
GitHub MCP Server是一个让OpenClaw能够调用GitHub API的MCP服务。它支持仓库操作、Issue管理、PR创建、CI状态查询等能力。
步骤1:生成GitHub Personal Access Token
- 登录GitHub → Settings → Developer settings → Personal access tokens → Tokens (classic)
- 点击“Generate new token (classic)”
- 勾选权限:
repo(完整仓库访问)、workflow(CI/CD)、write:discussion - 生成后复制token(仅显示一次,请妥善保存)
步骤2:在OpenClaw中配置MCP Server
编辑~/.openclaw/openclaw.json,添加:
json
{
"mcpServers": {
"github": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-github"],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "your_token_here"
}
}
}
}
步骤3:验证工具加载
bash
openclaw mcp list # 应看到 github_* 系列工具,如 github_create_issue, github_create_pr
21.3.2 Supervisor Agent自动处理Issue
当新的Issue被创建时,GitHub webhook可以触发Supervisor Agent开始工作。
在Supervisor Agent的AGENTS.md中添加:
markdown
## 自动任务(当检测到新Issue时) 1. 调用 `github_get_issue` 获取Issue详情 2. 分析Issue类型: - 如果是Bug → 调用开发Agent分析修复 - 如果是Feature Request → 标记“待规划” - 如果是Question → 直接回复 3. 开发完成后,调用 `github_create_pr` 创建Pull Request 4. 在PR描述中自动添加“Fixes #xxx”
用户侧(飞书)如何触发:直接在飞书里@Supervisor Agent说:
“@DevOps Supervisor 请帮我处理#142号Issue的登录超时Bug,修复后提交PR”
Agent会完成从获取Issue到创建PR的全过程。
21.3.3 开发Agent的代码修复Skill
创建一个Hermes Skill专门用于代码分析与修复。
SKILL.md(~/.hermes/skills/code_fixer/SKILL.md):
markdown
--- name: code_fixer description: 分析代码仓库中的Bug,生成修复方案并应用 --- ## 工作流 1. 使用 `git clone` 拉取仓库(如果尚未克隆) 2. 根据Issue描述定位相关代码文件 3. 分析代码逻辑,判断可能的错误原因 4. 生成修复代码(diff格式或直接替换) 5. 运行单元测试验证修复(`pytest tests/`) 6. 若测试通过,提交变更;若失败,分析原因并调整 7. 输出修复报告,包含变更文件和测试结果 ## 约束 - 仅修改与Issue直接相关的文件,不得擅自重构无关代码 - 修复后必须运行测试,不通过的修复不能提交
21.3.4 开发-测试-部署流水线中的Agent交接(OpenClaw子Agent委托)
这个流水线展示了如何通过子Agent委托实现开发→测试→部署的自动流转。
使用OpenClaw子Agent委托实现开发流程自动化:
bash
# 示例:Supervisor Agent通过子Agent委托执行完整CI/CD openclaw subagent spawn code_fixer \ "分析Issue #142关于登录超时的报告,定位问题在auth/middleware.go第47-52行,修复该区域并确保测试通过" # 测试Agent在后台运行测试套件 openclaw subagent spawn test_agent \ "对PR分支执行完整的pytest测试套件,标记失败的测试用例" # 测试通过后自动触发部署子任务 openclaw subagent spawn deploy_agent \ "将修复后的代码部署到staging环境,执行健康检查"
每个子Agent在独立的会话中运行,任务隔离,互不干扰,父Supervisor Agent只需等待最终汇总结果。
龙马注:我在实盘部署中使用 isolated模式运行每个Cron任务,确保构建任务失败不会影响主对话会话。“构建Agent”和“测试Agent”各自独立,互不干扰,即使一个子Agent崩溃,其他Agent仍可继续工作。建议在Cron任务中使用--session isolated。
🛠️ 实践任务(本节):
- 配置GitHub MCP Server,测试
github_list_issues工具是否能正常获取Issue列表 - 创建一个简单的“问候语”PR的自动化流程(先手动触发,再尝试webhook)
- 记录整个流程的执行日志,标注每个环节耗时
21.4 故障自愈机制
🎯 本节目标:设计自动故障检测与修复机制,配置健康检查,实现服务自愈。
预计时长:1小时
21.4.1 健康检查与自动恢复架构
故障自愈是一个三级阶梯:检测 → 诊断 → 恢复。三个环节分别由不同Agent负责,形成闭环。
┌─────────────────────────────────────────────────────┐
│ 检测层 │
│ 监控Agent(Heartbeat)→ 发现服务状态异常 │
└─────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ 诊断层 │
│ 诊断Agent(Hermes)→ 分析日志、定位根因 │
└─────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ 恢复层 │
│ 执行Agent → 重启服务 / 回滚版本 / 切换流量 │
└─────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ 审计层 │
│ 审计Agent → 记录恢复操作、更新知识库 │
└─────────────────────────────────────────────────────┘
21.4.2 监控配置(Heartbeat + Cron双机制)
OpenClaw提供了Cron和Heartbeat两种自动化机制:
- Cron:时间精确,适合固定时间的重任务(每日备份、每周报告)
- Heartbeat:上下文感知的周期性检查,适合高频轻量轮询(服务状态、收件箱)
Cron定时巡检示例(每日9点准时输出健康报告):
bash
openclaw cron add --name "daily_health_check" \ --cron "0 9 * * *" --tz Asia/Shanghai \ --message "检查所有生产服务健康状态,输出报告到飞书群" \ --session isolated
Heartbeat高频轮询示例(每30秒检测一次关键API):
Heartbeat在完整会话上下文中运行,适合需要历史对话信息的智能检查。Heartbeat每隔一段时间触发一次,运行HEARTBEAT.md清单中的所有任务。配置方法:
- 在
~/.openclaw/workspace/HEARTBEAT.md中编写检查清单 - 在
config.yaml中配置agents.defaults.heartbeat.every: "30s" - 重启Gateway生效
Heartbeat是模糊巡检,它的任务是“批量执行、状态感知”,适合高频轻量级监控;Cron是精确定时器,适合确定性时间点的批量任务。
21.4.3 诊断Agent的故障分析流程
当监控Agent发现异常时,触发诊断Agent深入分析。
诊断Agent的SKILL.md:
markdown
---
name: diagnostic_agent
description: 分析服务故障日志,定位根因,给出修复建议
---
## 工作流
1. 接收告警信息(服务名、时间、错误摘要)
2. 使用 `log_fetch` 工具获取该服务的错误日志(最近30分钟)
3. 使用 `web_search` 搜索类似错误的解决方案
4. 分析错误模式:
- 如果是 OOM → 检查内存使用趋势,建议扩容或排查内存泄漏
- 如果是 DB 连接超时 → 检查连接池配置、数据库负载
- 如果是 500 错误 → 分析调用栈,定位具体代码行
5. 输出诊断报告,包含:
- 根因推断(最可能的原因)
- 验证步骤(如何确认)
- 修复建议(短期+长期)
## 输出格式
```json
{
"service": "auth-api",
"error_type": "DB_TIMEOUT",
"root_cause": "连接池 max_open=10 不足,高峰期请求排队超时",
"short_term_fix": "临时将 max_open 调整为 50",
"long_term_fix": "配置 PgBouncer 连接池,
"verification": "执行 pg_stat_activity 查看活跃连接数"
}
沈飞注:这个诊断流程直接复用于量化系统的策略回测失败分析——回测Agent发现异常后,诊断Agent自动分析是数据源问题、代码Bug还是市场结构变化导致的失效,为研究员提供第一手判断,是实盘中不可或缺的能力。
21.4.4 自动恢复与回滚
自动恢复需要谨慎设计——恢复操作本身可能引发更大问题。采用“分级恢复”策略。
恢复类型与审批策略:
| 恢复类型 | 操作 | 是否需要审批 | 适用场景 |
|---|---|---|---|
| 重启服务 | 调用kubectl rollout restart | 否(自动执行) | 临时性故障、内存泄漏 |
| 切换流量 | 更新负载均衡权重 | 是(飞书审批) | 部分实例异常 |
| 回滚版本 | 部署上一个稳定版本 | 是(飞书审批) | 新版本引入严重Bug |
| 扩容资源 | 增加Pod/内存副本 | 是(飞书审批) | 负载持续上升 |
检查点回滚机制:在部署前自动创建环境快照,一旦健康检查失败可立即回滚。
json
// openclaw.json 中配置
{
"deployment": {
"pre_deploy_snapshot": true,
"health_check_timeout": 60,
"rollback_on_failure": true,
"rollback_require_approval": false // 自动回滚无需审批
}
}
熔断机制:当短时间内连续失败(例如5分钟内3次部署失败),自动熔断,暂停所有自动化部署任务,并发送紧急告警到飞书@负责人。
熔断配置示例:
yaml
circuit_breaker: enabled: true failure_threshold: 3 # 连续失败3次后熔断 timeout_seconds: 300 # 5分钟后自动恢复探测 half_open_requests: 1 # 探测成功则关闭熔断器
21.4.5 实战:服务自动恢复(45秒搞定OOM)
以一个真实场景为例:某服务报“out of memory”错误。
- 检测:Heartbeat每30秒调用
/health端点,收到500错误,标记异常。 - 诊断:诊断Agent拉取该服务的错误日志,确认为内存不足。
- 恢复:执行Agent尝试重启服务(
kubectl rollout restart)。 - 验证:再次调用
/health,确认恢复成功。 - 记录:审计Agent将此次事件写入共享记忆,供复盘使用。
整个流程从告警到恢复完成,典型耗时45秒。用户在飞书中只收到两条消息:一条“检测到auth-api异常,正在诊断”,另一条“已重启服务,健康检查通过”。
龙马注:自动恢复的“度”值得反复推敲。我的经验:重启服务可以自动化,回滚版本需审批。一旦配置了自动回滚,务必设置严格的健康检查窗口——至少在5分钟内检测服务是否稳定,避免恶性循环。每次故障处理完成后,审计日志会记录完整的处理链路——也是模型自我优化的真实原料。
21.5 多人开发场景下的权限与代码审查流程强化(仍为一人指挥多Agent)
🎯 本节目标:虽然是一人多Agent,但你指挥的Agent可以扮演不同角色——开发Agent、审查Agent、审计Agent相互配合,形成制衡。
预计时长:0.3小时
21.5.1 三层权限模型
即使只有你一个人,让不同Agent扮演不同角色仍然有价值——它能让你在指挥层面实施“职责分离”,避免一个Agent拥有过高权限。在你的“一人公司”中,可以设计三种权限级别的Agent:
| Agent类型 | 可执行操作 | 权限来源 | 典型Agent |
|---|---|---|---|
| 只读Agent | 查看代码、查看日志、查看配置 | 最小权限 | 审计Agent、监控Agent |
| 操作Agent | 修改代码、创建PR、运行测试 | 需审批 | 开发Agent、测试Agent |
| 管控Agent | 部署生产、修改权限、变更配置 | 强制审批+双人确认 | 部署Agent |
虽然是“一人”公司,但Agent之间的权限制衡仍然是安全底线。生产环境部署Agent拥有最高权限,但它必须经过审批才能执行——这个审批者就是你本人。
21.5.2 代码审查Agent自动拦截
在创建PR时,审查Agent自动运行,发现问题时拒绝合并:
bash
# 审查Agent运行结果示例 ❌ 审查未通过 - 函数 calculate() 圈复杂度 15 > 10 - 发现未处理的异常: line 47 - 单元测试覆盖率 62% < 80% 建议: 重构calculate函数, 添加异常处理
审查Agent不会自动修改代码,但会给出明确建议,由你决策。你可以告诉开发Agent:“根据审查意见修复”,开发Agent会按清单逐项改进。
21.6 🔗 量化场景类比:CI/CD流水线与策略回测–实盘上线流水线
🎯 本节目标:将开发运维的自动化流水线映射到量化交易的策略部署流程。
预计时长:0.2小时
核心映射关系
| 开发运维环节 | 量化交易对应环节 |
|---|---|
| GitHub Issue(Bug报告) | 策略回测失败报告(夏普比率下降) |
| 开发Agent修复代码 | 策略优化Agent调整参数/回测验证 |
| 测试Agent运行单元测试 | 回测Agent验证新策略在新数据上表现 |
| 审查Agent代码审查 | 风控Agent策略准入审查(最大回撤、夏普、胜率) |
| 构建Agent打包镜像 | 策略封装为Signal Agent |
| 部署Agent上线(需审批) | 交易Agent实盘上线(需风控审批) |
| 健康检查 | 风控Agent实时监控持仓 |
| 回滚 | 熔断机制/降级策略 |
自动化流水线复用
开发运维中的“Issue → 修复 → 测试 → 审查 → 上线”流水线,与量化中的“回测失败报告 → 策略优化 → 回测验证 → 风控审查 → 实盘上线”完全对应。
你需要复用的组件:
- Supervisor Agent的调度逻辑
- 审批流程配置(
requireApproval) - 健康检查与回滚机制
- 审计日志记录(
audit_enabled: true)
在第五篇中,你只需将这些模式中的“代码修复/测试/部署”替换为“策略优化/回测/上线”,即可快速搭建量化策略的CI/CD流水线。
沈飞注:这个类比非常关键。实盘中,量化策略的上线流程必须像软件开发一样严谨——策略代码版本管理(Git)、回测结果自动生成报告、风控审查后才能信号进入实盘,每一步都与CI/CD理念完全一致。如果你学完本节能画出一张“策略CI/CD流水线图”,第五篇的学习会事半功倍。
🛠️ 实践任务(本节):画出从“策略回测失败”到“新策略上线”的自动化流程,标注哪些环节复用开发运维的配置。
第21章 参考资料与扩展阅读
- CI&T基于Amazon Bedrock AgentCore与OpenClaw的企业级智能运维最佳实践 https://aws.amazon.com/cn/blogs/china/ci-t-based-on-amazon-bedrock-agentcore-openclaw-enterprise-intelligent-operations-best-practices/
- 用AI管理k8s:阿里云部署Hermes Agent/OpenClaw+集成K8s集群Skill https://developer.aliyun.com/article/1731324
- OpenClaw 自动化工作流进阶:Cron与Heartbeat的智能协同实践 https://developer.baidu.com/article/detail.html?id=6620681
- OpenClaw 高级配置完整指南——子Agent调度、Cron定时任务、Skill开发 https://developer.aliyun.com/article/1718408
- 自动化与任务——OpenClaw官方文档 https://docs.openclaw.ai/zh-CN/automation
- 定时任务(Cron)——OpenClaw官方文档 https://docs.openclaw.ai/zh-CN/automation/cron-jobs
- Scheduled tasks (cron)——OpenClaw官方文档(英文)https://docs.openclaw.ai/automation/cron-jobs
- GitHub Actions MCP Server——让AI助手关注CI/CD流水线 https://github.com/github-actions-mcp
- Docker部署Hermes Agent完整指南 https://developer.aliyun.com/article/1730664
第四篇综合任务(第21章完成后)
任务:完成以下所有检查项,并记录输出。
- 配置GitHub MCP Server,成功获取项目Issue列表
- 创建Supervisor Agent,测试至少2种不同任务类型的调度(如“修复Bug”和“部署服务”)
- 配置至少一个Cron定时任务(如每日健康检查),验证报告自动推送
- 模拟一次服务故障(如通过脚本kill进程),验证诊断→恢复链路
- 审批配置测试:设置部署Agent需审批,模拟一次部署请求并批准
- (可选)编写一个code_fixer Skill,用Hermes修复一个已知小Bug(使用本地测试仓库)
完成后,保存配置文件和测试日志,命名为chapter21_devops_config.zip。
龙马的评审:
“21.3节的子Agent委托是我日常最频繁使用的模式。Supervisor Agent作为一个‘项目总管’,把所有专业Agent串联起来——你只需要对它说话,不需要关心哪个Agent来执行。这个设计模式在第五篇量化中同样关键——策略研发、回测、风控、执行都可以各自独立为一个Agent,由总调度Agent统管。
权限控制方面,生产部署必须加审批。我在那之后将生产部署单独划出一个 deploy_agent,只开放部署权限同时绑定审批流程。部署失败时自动回滚到上一个稳定版本,不需要人工介入。”
沈飞的评审:
“21.4节的故障自愈与熔断机制,在量化系统中直接对应风控熔断。市场剧烈波动时,风控Agent应当自动降级——停止开新仓、逐步平仓、甚至切换至保守策略。CI/CD的“健康检查→诊断→恢复”流程,完全可以复用为“行情异常→归因分析→策略切换”。
我们在实盘中配置了三个熔断级别:一级(策略单日亏损超3%)→停止该策略信号;二级(产品总回撤超8%)→全部策略暂停;三级(技术故障)→程序自动止损。每个级别的恢复都需要人工确认,正如CI/CD部署需要审批一样。”
下一章预告:第22章 一人多Agent公司的最佳实践与进阶 —— 我们将总结前三章的通用模式,提供五步设计法、扩展流程、代码片段库,帮助你为自己的业务快速搭建多Agent系统。













暂无评论内容