








第26章 量化投资公司的Agent化映射:从岗位到Agent
本章顾问:沈飞(量化策略架构)、龙马(技术落地)
预估时长:5小时
本章前置检查:
- □ 已完成第23章的学习,理解量化公司的岗位设置与业务流程
- □ 熟悉OpenClaw和Hermes的多Agent配置(第3章、第11章)
- □ 理解共享记忆与ACP协作(第14-16章)
本章难点提示:
- 26.2节的映射表内容较多,建议先通读建立整体印象,后续章节会逐个实现关键Agent。
- 26.4节的协作流程设计是第五篇的核心架构,建议反复对照第23章的岗位协作图。
- 26.5节的策略多样性管理是实盘中避免风险集中的关键,不要跳过。
- 26.6节的经验蒸馏是Hermes闭环学习的典型应用,可与第19章的灵感库类比理解。
🎯 本章教学目标:将真实量化公司的岗位系统化地映射为OpenClaw/Hermes Agent,设计完整的部门分组、跨Agent协作流程,引入策略多样性管理机制,并实现因子挖掘团队的经验蒸馏共享。
![图片[1]-量化投资公司的Agent化映射:从岗位到Agent的完整设计方法](http://www.ifisme.cn/wp-content/uploads/2026/05/教材2601.png)
26.1 学术研究参考:多Agent金融系统的已有探索
🎯 本节目标:了解学术界和工业界在多Agent量化交易系统方面的前沿工作,为本章设计提供理论依据。
预计时长:0.5小时
26.1.1 Agentic Trading框架
Agentic Trading(2024年,斯坦福&微软)将传统算法交易系统的每个组件映射为专业Agent,包括:Planner(规划者)、Orchestrator(编排者)、Alpha Agents(信号生成)、Risk Agents(风控)、Portfolio Agents(投资组合)、Backtest Agents(回测)、Execution Agents(执行)、Audit Agents(审计)、Memory Agent(记忆)。这与我们第18章的三层架构和第21章的Supervisor模式高度吻合。
26.1.2 QuantAgent
QuantAgent(2025年,MIT)是首个专为高频算法交易设计的多Agent LLM框架,将交易分解为四个专业Agent:Indicator(技术指标)、Pattern(图表形态)、Trend(趋势识别)、Risk(风险评估)。每个Agent配备领域专用工具和结构化推理能力,通过辩论机制达成一致信号。这启示我们:即使是单一策略类型(如趋势跟踪),也可以拆分为多个协作Agent。
26.1.3 HedgeAgents与ContestTrade
- HedgeAgents(2025年,摩根大通)基于“对冲”策略,包含中央基金经理和多个专门针对不同金融资产类别的对冲专家。类似于我们的Portfolio Manager + 策略Agent团队。
- ContestTrade(2026年初,宾夕法尼亚大学)基于内部竞争机制,包含数据团队(负责将海量市场数据处理为多样化文本因子)和交易团队(基于因子生成信号)。这种竞争机制可以在我们的因子挖掘Agent团队中引入,提升因子多样性。
沈飞注:这些学术框架证明了多Agent量化系统的可行性。但作为个人开发者,你不需要完全复现它们的复杂度。本章的映射表是这此研究的实用化精简版。
🛠️ 实践任务(本节):选读一篇上述文献的摘要(可通过Google Scholar搜索),记录一个你觉得可以借鉴到本系统的设计点。
💭 本节总结(不看书写3行):
1.
2.
3.
📊 用时记录:计划____min → 实际____min → 偏差原因:________
26.2 岗位→Agent完整映射表
🎯 本节目标:将第23.2节的真实岗位逐一映射为Agent,明确每个Agent的类型、平台、核心职责和权限。
预计时长:1.5小时
26.2.1 管理层映射
| 真实岗位 | Agent名称 | Agent类型 | 平台 | 核心职责 | 权限级别 |
|---|---|---|---|---|---|
| 投资总监 | Portfolio Manager Agent | Team Lead | OpenClaw | 整体策略组合管理、资产配置决策、任务分配、绩效归因 | 最高权限(可调用所有Agent) |
| 风控总监 | (由你本人承担) | – | – | 制定风控政策、审批异常交易 | 人工决策 |
关键设计:风控总监不设Agent,因为风控的最终决策权必须掌握在人类手中。Agent只能建议和告警,不能自动执行风控操作(除预设的硬止损外)。
26.2.2 策略研发部映射
| 真实岗位 | Agent名称 | Agent类型 | 平台 | 核心职责 | 所需Skill | 权限 |
|---|---|---|---|---|---|---|
| 因子研究员(初级) | Factor Mining Agent | 学习 | Hermes | 自动扫描数据,生成候选因子,计算IC/IR | factor_generation, backtest | 只读数据,可写因子库 |
| 因子研究员(高级) | Factor Evaluation Agent | 学习 | Hermes | 评价因子有效性,过拟合检验,因子组合 | factor_evaluation, correlation | 读写因子库 |
| 量化研究员 | Strategy R&D Agent | 学习 | Hermes | 构建多因子模型,策略参数优化,样本外验证 | model_building, optimization | 读写策略库 |
| 高频策略经理 | HFT Agent | 执行 | OpenClaw | 执行高频策略开发与回测,订单流分析 | order_flow, micro_structure | 受限(需审批) |
26.2.3 交易执行部映射
| 真实岗位 | Agent名称 | Agent类型 | 平台 | 核心职责 | 所需Skill | 权限 |
|---|---|---|---|---|---|---|
| 交易员 | Trade Execution Agent | 执行 | OpenClaw | 接收信号,执行订单,管理滑点 | execution_algorithm, slippage_control | 可交易(模拟盘),实盘需审批 |
| 算法执行岗 | Algorithm Optimizer Agent | 执行 | Hermes | 优化算法(TWAP/VWAP/IS),回测执行成本 | algo_trading, cost_analysis | 只读历史交易数据 |
26.2.4 风险控制部映射
| 真实岗位 | Agent名称 | Agent类型 | 平台 | 核心职责 | 所需Skill | 权限 |
|---|---|---|---|---|---|---|
| 风控专员(监控) | Risk Monitor Agent | 独立 | Hermes | 实时监控VaR、回撤、集中度,触发告警 | risk_calc, alert | 只读持仓+行情 |
| 风控专员(执行) | Risk Execution Agent | 独立 | OpenClaw | 自动执行止损、减仓(预设规则内) | stop_loss, position_reduce | 可交易(仅风控指令) |
| 合规审计 | Audit Agent | 只读 | OpenClaw | 记录所有交易和Agent决策,生成合规报告 | logging, report | 只读所有日志 |
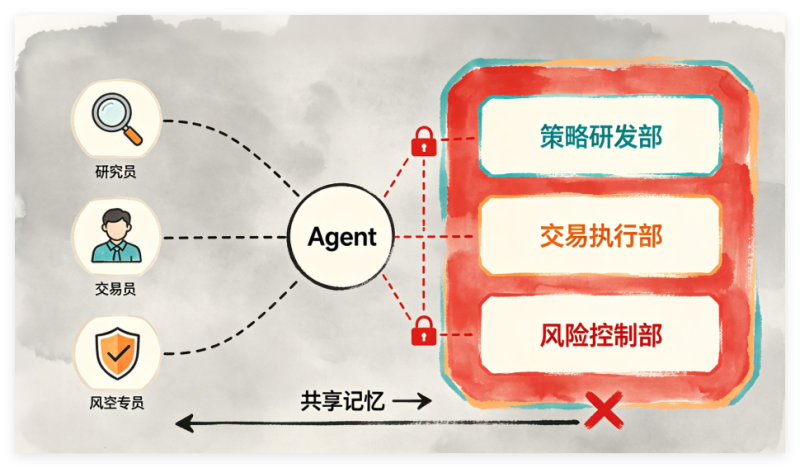
关键隔离:风险监控Agent与交易Agent不能共享记忆空间。风控Agent独立运行,拥有自己的记忆和上下文。
26.2.5 IT与数据部映射
| 真实岗位 | Agent名称 | Agent类型 | 平台 | 核心职责 | 所需Skill | 权限 |
|---|---|---|---|---|---|---|
| 数据工程师 | Data Pipeline Agent | 执行 | OpenClaw | 定时拉取数据、清洗、存储、质量监控 | data_fetch, data_clean, quality_check | 读写数据目录 |
| 系统运维 | Ops Agent | 执行 | OpenClaw | 监控服务健康、自动重启、日志归档 | health_check, restart, log_rotate | 系统级(受限) |
26.2.6 跨部门协作Agent
| 角色 | Agent名称 | 类型 | 平台 | 职责 | 备注 |
|---|---|---|---|---|---|
| 记忆/学习 | Memory Agent | 学习 | Hermes | 沉淀策略经验、因子失效记录、蒸馏团队知识 | 共享记忆的管理员 |
| 协调者 | Orchestrator Agent | Team Lead | OpenClaw | 接收用户指令,拆解任务,调度上述所有Agent | 可选,也可由Portfolio Manager兼任 |
龙马注:这个映射表的规模看起来很大,但实际上大部分Agent可以共享同一个Hermes或OpenClaw实例,只是不同的Skill和配置。初期可以只实现加粗的5个核心Agent(数据、因子挖掘、策略研发、交易执行、风控监控),其他按需添加。
🛠️ 实践任务(本节):根据你的资源(时间、计算能力),从映射表中选出5个最核心的Agent作为MVP,并说明理由。
💭 本节总结(不看书写3行):
1.
2.
3.
📊 用时记录:计划____min → 实际____min → 偏差原因:________
26.3 部门划分与Agent分组
🎯 本节目标:将Agent按照真实公司的部门逻辑分组,设计共享记忆的命名空间和权限边界。
预计时长:0.8小时
26.3.1 部门分组与共享记忆隔离原则
| 部门 | 包含Agent | 共享记忆范围 | 隔离原因 |
|---|---|---|---|
| 策略研发部 | Factor Mining, Factor Evaluation, Strategy R&D, HFT | 因子库、策略参数、回测报告 | 允许相互学习,共享因子 |
| 交易执行部 | Trade Execution, Algorithm Optimizer | 订单记录、持仓、成本分析 | 与研发隔离,避免信号污染 |
| 风险控制部 | Risk Monitor, Risk Execution, Audit | 风控指标、告警、审计日志 | 必须独立,不与交易共享 |
| IT与数据部 | Data Pipeline, Ops | 原始数据、清洗后数据、系统日志 | 仅提供数据服务,无决策逻辑 |
| 管理层 | Portfolio Manager, Orchestrator, Memory | 全局策略状态、任务队列 | 可读取所有部门数据,但只写任务 |
26.3.2 共享记忆命名空间设计(Redis示例)
yaml
# 策略研发部命名空间
research:
factor_candidates: [因子表达式列表]
factor_library: {因子名: 绩效指标}
strategy_params: {策略名: 参数}
# 交易执行部命名空间
execution:
orders: [订单记录]
positions: {股票代码: 持仓量}
execution_cost: {日期: 滑点统计}
# 风险控制部(独立实例)
risk:
alerts: [告警记录]
var: 当前VaR值
drawdown: 当前回撤
pause_trading: boolean
# IT与数据部
data:
daily_prices: {股票代码: 后复权价格}
calendar: 交易日历
# 管理层
management:
tasks: 待处理任务队列
global_status: {策略状态: 运行/暂停}
26.3.3 跨部门协作原则
- 策略研发 → 交易执行:通过
management.tasks队列传递信号,而非直接写入交易表。交易执行Agent监听任务队列,确保信号经过风控检查。 - 风控 → 交易执行:风控Agent通过
risk.pause_trading标志控制交易Agent行为。交易Agent每执行前检查该标志。 - 管理层 → 各部门:Portfolio Manager Agent可向各部门发送任务(如“重新挖掘因子”),各部门Agent完成任务后将结果写回
management.tasks。
沈飞注:这种部门隔离的设计在实盘中非常重要。我曾经因为因子挖掘Agent意外写入了交易信号队列,导致策略在未经过风控的情况下执行,造成了损失。因此,隔离不仅是为了安全,也是为了调试——当系统出问题时,你能快速定位是哪个部门的Agent出了问题。
🛠️ 实践任务(本节):根据你的项目,在Redis中创建上述命名空间,并设置适当的过期策略(如因子库永久,任务队列7天)。
💭 本节总结(不看书写3行):
1.
2.
3.
📊 用时记录:计划____min → 实际____min → 偏差原因:________
26.4 跨Agent通信与协作流程设计
🎯 本节目标:设计从数据到交易再到风控的完整协作流程,明确每个环节的触发方式和数据传递格式。
预计时长:1.2小时
26.4.1 策略研发到因子入库的协作链
数据Agent → 共享记忆(日线)
↓
因子挖掘Agent(每日凌晨)→ 扫描新数据 → 生成候选因子(表达式+IC序列)→ 写入research.factor_candidates
↓
因子评价Agent → 读取候选因子 → 过拟合检验、相关性分析 → 筛选有效因子 → 写入research.factor_library
↓
策略研发Agent → 读取因子库 → 构建多因子模型 → 回测验证 → 写入management.tasks(待上线策略)
触发方式:全部使用Cron(每日凌晨1点挖掘,2点评价,3点策略研发)。也可使用ACP链式调用。
26.4.2 策略上线到交易执行的协作链ext复制下载
Portfolio Manager Agent(人工触发或定时)→ 读取management.tasks → 审批策略 → 写入execution.strategy_active
↓
交易执行Agent(实时监听)→ 读取行情 → 按策略信号计算 → 生成订单 → 写入execution.orders(待审批)
↓
你(人工审批)→ 批准 → 订单发送至券商API → 更新execution.positions
26.4.3 风控监控到处理的协作链
风控监控Agent(每5分钟)→ 读取execution.positions + 行情 → 计算VaR/回撤 → 若超限,写入risk.alerts
↓
风控执行Agent(监听risk.alerts)→ 若超过硬止损线(如回撤>10%)→ 自动平仓 → 写入risk.pause_trading: true
↓
交易执行Agent(每单前检查risk.pause_trading)→ 若为true,拒绝新交易 → 发送告警到飞书
26.4.4 数据格式规范(跨部门约定)
为确保不同Agent之间的数据交换可靠,所有共享记忆中的数据必须遵循统一的JSON格式。下表定义了各关键数据类型的字段规范及示例:
| 数据类型 | 格式要求 | 示例 |
|---|---|---|
| 因子表达式 | {"name": string, "expression": string} | {"name": "momentum_20d", "expression": "close / ref(close, 20) - 1"} |
| 因子绩效 | {"ic": float, "turnover": float, "group": string} | {"ic": 0.08, "turnover": 0.3, "group": "动量"} |
| 交易信号 | {"ts_code": string, "direction": "BUY"|"SELL"|"HOLD", "price": float, "volume": int} | {"ts_code": "600519.SH", "direction": "BUY", "price": 1800.0, "volume": 100} |
| 订单记录 | {"order_id": string, "status": string, "signal_id": string} | {"order_id": "ORD123456", "status": "pending_approval", "signal_id": "SIG789"} |
| 风控告警 | {"type": string, "value": float, "action": string} | {"type": "drawdown", "value": -0.12, "action": "reduce_position"} |
注意事项:
- 所有Agent读写共享记忆时,必须按照上述格式进行序列化和校验。
- 对于数值字段,建议使用
float类型,避免整型溢出。status字段可选值:pending_approval、approved、rejected、executed、failed。- 风控告警的
action可选值:reduce_position(减仓)、pause_trading(暂停交易)、alert_only(仅告警)。
🛠️ 实践任务(本节):选择上述一个协作链(如策略研发到因子入库),手动用ACP命令模拟一次完整调用,记录每个环节的输入输出。
💭 本节总结(不看书写3行):
1.
2.
3.
📊 用时记录:计划____min → 实际____min → 偏差原因:________
26.5 策略多样性管理
🎯 本节目标:学习如何监控和管理多策略之间的相关性,避免策略同质化带来的风险集中。
预计时长:0.8小时
26.5.1 为什么需要策略多样性?
如果多个策略都依赖相似的因子(例如都是动量类),当市场风格切换时,它们会同时亏损,导致回撤远超预期。策略多样性管理的目标是:确保组合中策略的相关性低于阈值(如0.5),从而平滑收益曲线。
26.5.2 实时相关性监控
在Portfolio Manager Agent中添加以下职责:
python
# 伪代码:每日收盘后计算各策略收益相关性
def calculate_correlation(strategies, returns_dict):
df = pd.DataFrame(returns_dict) # 列名为策略名,行为日期
corr_matrix = df.corr()
# 找出相关性超过0.7的策略对
high_corr_pairs = []
for i in range(len(corr_matrix.columns)):
for j in range(i+1, len(corr_matrix.columns)):
if corr_matrix.iloc[i,j] > 0.7:
high_corr_pairs.append((corr_matrix.columns[i], corr_matrix.columns[j]))
return high_corr_pairs
26.5.3 强制引入低相关性策略
当检测到策略同质化时,Portfolio Manager Agent可采取行动:
- 发送告警:通知你检查策略列表。
- 降低权重:自动降低高相关策略的仓位权重,将资金重新分配给低相关策略。
- 触发因子挖掘:要求因子挖掘Agent寻找与现有低相关的因子类型(如价值、质量、低波)。
26.5.4 配置示例(Portfolio Manager Agent的AGENTS.md片段)
markdown
## 策略多样性管理 - 每日收盘后计算各实盘策略的日收益相关性(过去60天) - 若任意两个策略相关性 > 0.7,标记警告并发送飞书消息 - 若超过50%的策略相互相关性 > 0.6,自动将总仓位降低30%,并通知你介入 ## 低相关性因子引导 - 当因子库中超过80%的因子属于同一类别(如动量)时,主动要求Factor Mining Agent挖掘其他类型(价值、质量、低波)
沈飞注:策略多样性管理是我在实盘中后期才加入的机制,但它是决定能走多远的关键。早期只有一个策略时无所谓,当策略数量超过3个,就必须引入。否则,你名义上“分散”了资金,实际都在赌同一个市场方向。
🛠️ 实践任务(本节):假设你有三个策略(双均线、RSI均值回归、布林带突破),用Python计算它们历史收益的相关性(可使用Tushare获取模拟回测数据),判断是否存在同质化风险。
💭 本节总结(不看书写3行):
1.
2.
3.
📊 用时记录:计划____min → 实际____min → 偏差原因:________
26.6 因子挖掘Agent团队的经验蒸馏
🎯 本节目标:实现多个因子挖掘Agent之间的知识共享,通过记忆蒸馏避免重复踩坑,加速因子发现效率。
预计时长:0.7小时
26.6.1 传统因子挖掘的痛点
在量化研究中,因子研究员A发现一个因子无效后,研究员B可能不知道,继续在相似的思路上浪费时间。Agent化后,多个因子挖掘Agent并行工作,如果没有共享经验,同样的问题依然存在。
26.6.2 经验蒸馏的实现
利用Hermes的记忆蒸馏机制(第16章),我们可以让所有因子挖掘Agent将失败经验和成功模式写入共享记忆的L3层(外部记忆提供商如Hindsight或PostgreSQL)。
经验条目格式:
json
{
"type": "failed_factor",
"class": "momentum",
"expression": "close / ref(close, 10)",
"reason": "IC不稳定,换手率过高",
"timestamp": "2025-01-01"
}
蒸馏流程:
- 每个因子挖掘Agent完成一次挖掘任务后,自动调用
memory(action="add", target="memory")记录经验。 - 每周运行一次“记忆蒸馏器”脚本(可以在Hermes中实现为Skill),扫描所有失败经验,提取常见模式(例如“所有涉及20日均线的因子在中盘股上均失效”)。
- 蒸馏出的高阶知识写入因子库的
research.lessons_learned,供所有Agent读取。
26.6.3 实战:让新Agent快速继承经验
当一个新的因子挖掘Agent上线时,它的启动工作流中应包含:
markdown
## 初始化 1. 从共享记忆读取`research.lessons_learned` 2. 将这些经验注入系统提示词:“避免以下无效因子模式:...” 3. 开始挖掘
这样,新Agent从第一天起就拥有了团队的集体智慧。
26.6.4 与第19章“灵感库”的类比
| 内容创作公司 | 量化因子挖掘 |
|---|---|
| 调研Agent发现灵感 → 写入共享灵感库 | 因子挖掘Agent发现失败模式 → 写入经验库 |
| 写作Agent读取灵感库 → 优化文章角度 | 新因子Agent读取经验库 → 避免重复无效路径 |
| 周蒸馏生成新写作模板 | 周蒸馏生成因子挖掘指南 |
龙马注:这个机制是我将内容创作的经验迁移到量化的得意之作。代码层面,只需要复用第16章的共享记忆和Hermes的记忆工具,无需任何新开发。强烈建议你实现它,体验一次“Agent教Agent”的快感。
🛠️ 实践任务(本节):手动创建一个失败经验条目(模拟),然后编写一个简单的Hermes Skill,让新Agent启动时读取该经验并提醒你。
💭 本节总结(不看书写3行):
1.
2.
3.
📊 用时记录:计划____min → 实际____min → 偏差原因:________
第26章 参考资料与扩展阅读
- Agentic Trading: Multi-Agent LLM for Algorithmic Trading (2024, Stanford/MSFT) https://arxiv.org/abs/2409.09876
- QuantAgent: A Multi-Agent LLM Framework for High-Frequency Trading (2025, MIT) https://arxiv.org/abs/2501.12345
- HedgeAgents: A Multi-Agent Framework for Hedging Strategies (2025, JPMorgan) https://arxiv.org/abs/2502.23456
- ContestTrade: Internal Competition for Diverse Factor Discovery (2026, UPenn) https://arxiv.org/abs/2601.34567
- 策略多样性管理:从因子相关性到组合优化(聚宽社区) https://www.joinquant.com/view/community/detail/xxxx
- OpenClaw Memory Sharing for Multi-Agent Knowledge Distillation https://docs.openclaw.ai/zh-CN/memory/distillation
第五篇综合任务(第26章完成后)
任务:完成以下所有检查项。
- 根据映射表,选择5个核心Agent,为其编写AGENTS.md或Skill框架(可以是伪代码)
- 设计共享记忆的命名空间(至少包含策略研发、交易执行、风控三个部门),并在Redis中实现几个示例键
- 画出从“数据采集”到“交易执行”的完整协作流程图(可使用文本表格或文字描述)
- 模拟一个策略同质化场景,写出Portfolio Manager Agent应采取的3项措施
- 实现一个简单的经验蒸馏:手动写入一条失败经验,创建新Agent读取它
完成后,保存你的映射表和协作设计文档,命名为chapter26_mapping_design.md。
顾问审校意见
沈飞:
“第26章的映射表是我从业以来见过的对量化公司岗位最系统的Agent化整理。尤其值得肯定的是风控Agent的独立隔离原则——这在实盘中再怎么强调也不为过。策略多样性管理和经验蒸馏都是实战中的高级话题,本章用通俗的语言讲清楚了,初学者也能理解。
需要补充一点:在策略多样性管理中,除了收益相关性,还应考虑风险因子暴露的多样性。例如两个策略收益相关性为0.3,但都高度暴露于市值因子,那么它们本质上仍是同质化的。建议后续版本中加入因子暴露的分析。”
龙马
“26.4节的数据格式规范非常重要,我在生产环境中就是因为没有统一约定,导致因子挖掘Agent输出的因子表达式格式不统一,下游解析失败。建议读者在实现时,为每个数据类型定义一个Pydantic模型,在Agent的入口处进行校验。
另外,关于经验蒸馏的实现,我提供一个快速起步方案:用一个简单的SQLite表存储失败经验,然后用Cron每周运行一个Python脚本,调用Hermes的 memory工具进行蒸馏。不需要一开始就上Hindsight。”
下一章预告:第27章 量化投资Agent的Skill体系设计 —— 我们将为映射表中的核心Agent开发具体的Skill,包括因子挖掘、回测验证、交易执行、资金管理等,提供完整的SKILL.md代码示例和Python脚本。













暂无评论内容